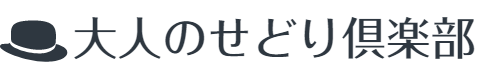

ども、まじめです。
今回はJanperに「HTMLファイルからリサーチ(仮)」という新機能が追加されたので、紹介します。
ご興味のある方は是非、ご覧下さい。
「HTMLファイルからリサーチ(仮)」とは
名前については仮称なので今後、変更されるかもしれませんが、
簡単に言えば、ショップや卸問屋の商品一覧ページのHTMLソースファイルからJANコードや価格等の情報を抽出しExcelファイルとして出力する機能になります。(複数ページを一度に処理できます。)
商品情報を抽出できるショップや卸問屋は順次追加予定です。(現在はカワダオンラインとNETSEAに対応しています。)
何故この機能を思いついたのか
カワダオンラインって商品リストをダウンロードしてリサーチすると、結構利益商品が見つかるんですが、いざ購入しようと思っても「在庫切れ」ってパターンが多いんです。
ダウンロードできる商品リストは1万件以上の商品が掲載されているんですが、更新頻度が遅いって欠点があります。
なので、リストの先頭にある更新日をチェックして、新しいファイルがアップされたら即リサーチする訳なんですが、それより気になるのが、カワダオンラインに会員登録すると届く、「カワダオンライン 11月28日から12月2日入荷の新商品をご案内いたします」みたいなタイトルのメール。
これってなかなか鮮度よさそうですよね。w
実際にKeepaの波形を見ても、ここ最近売れ始めている事がわかります。
要は「カワダオンラインのホームページの左メニューの「特集ページ」をリサーチできれば、面白いんじゃないか」というのが、この機能を思いついたきっかけです。
スクレイピングはアクセス制限される可能性が高いし、セレニウムの技術を使ったリサーチも今の僕には若干敷居が高い。w とはいっても、ただいま勉強中なので、実現もそう遠くはないと思いますけどね。
リサーチ手順は少し面倒
- まずはお目当てのページを開きログイン。
- Ctrl+Uでページのソースを表示。(開けない場合はURLの先頭に「view-source:」を付けてEnter)
- Ctrl+Aで全選択し、Ctrl+Cでコピー。
- Windowsならメモ帳を開き、Ctrl+Vで貼り付け。
- 複数ページをリサーチする場合は2~4を繰り返す。
- 全てのページのソースを貼り付けたら、Ctrl+Sで名前を付けて保存。
- Janperの「HTMLファイルからリサーチ」で6のファイルを指定し実行
- 7で出力されたファイルを「Excelファイルからリサーチ」でリサーチ
と、なかなか面倒くさそうですが、慣れれば早いもんです。w
実際にリサーチしてみた結果は
今回は実際に「11月21日~11月25日入荷の新商品」をリサーチしてみました。
こちらは1ページ12商品しかありませんでしたが、その結果は
1件の利益商品が見つかりました。現在はアマゾンも在庫切れで価格も上がっていますが、「キーゾン」の数値は3,2,1か月が1 → 4 → 31と順調です。(アマゾンの在庫も少なかったんですかね。)
ただし、この商品、僕が見たときは在庫残り僅かだったんですが、さっき見たらゼロになってました。(汗
一応、お気に入りに登録して「在庫更新通知メールを受け取る」にチェックを入れときました。
おもちゃカテゴリーは出品規制のかかっている商品も多いので、自分が出品できるのか確認して下さい。(または規制を解除できるのか)
その他のショップや卸問屋も絶賛募集中!
現在はカワダオンラインとNETSEAの2つですが、条件を満たしているショップまたは卸問屋なら対応可能なので、良いところがあれば、ご連絡下さいね。
条件は以下の通りです。
- 商品の一覧ページがある。(1ページ50商品以上が理想)
- 一覧ページ中にJANコードがある。(表面上にはなくてもソース中に隠れている場合もあります。→NETSEAとか)
スーパーデリバリーは残念ながら一覧ページからJANコードが取得できませんでした。
まとめ
いかがでしたか?
少し手間はかかりますが、楽天やヤフショ以外にもリサーチできるのは魅力的だと思います。
NETSEAだと1ページに60商品なので、手順2~4を20回繰り返せば1200件のデータが抽出できます。暇なときにでも是非チャレンジしてみて下さい。(1時間あれば1万件くらいできそうですが。)
ちなみにNETSEAには別の方法もありますので、興味のある方はこちらも参考にして下さい。
では、またー。

